All of Graphite’s data lives on Amazon Aurora Postgres.
Our database load is sizable — far larger than a typical startup of our size. This is because we sync bidirectionally with GitHub for everything a user does on Graphite, so Aurora plays a crucial role in helping us handle and scale massive amounts of data.
If Uber were to sign up for Graphite tomorrow, we could handle the countless webhook events triggered through their GitHub repos. But, our AWS bill would skyrocket due to a high volume of database operations.
Regardless of if one Uber engineer or a hundred sign up for Graphite, we’d still actively diff all of Uber’s GitHub activity against Graphite’s state in Aurora - mostly to power features like custom notifications. Our original implementation made our Aurora costs account for over 80% of our AWS bill, which paid for several thousand daily active users (roughly 4000 queries per second).
Try serverless?
Aurora prices on two things: storage rate and I/O rate. Our storage rate was affordable because our instance size was relatively cheap. But, our I/O rate was significantly more expensive because of our GitHub syncing.
We looked at Aurora Serverless to get our costs down. It sounded promising: Only pay for capacity that’s consumed. However, we constantly ingested so many updates via GitHub that it resulted in us needing such a large instance size on Aurora Serverless that it cost us more than if we chose a fixed instance size on Aurora. Furthermore, our traffic rarely experienced dramatic fluctuations, so we didn’t need the ability to upscale/downscale automatically.
But still, the issue with our high I/O costs on Aurora remained.
Christmas came early in May: Aurora I/O Optimized
On one foggy morning in late May, I opened the RDS console and found a pop-up that may as well have had a ribbon bow on top:


AWS released “Aurora I/O optimized”, a cost optimization feature that directly addressed our high I/O costs by offering up to 40% cost savings where I/O charges exceed 25% of the total Aurora database spend.
This feature would only charge us for a slightly higher storage rate but no I/O charges — making pricing more predictable. As CTO, I immediately began work to migrate our Aurora setup.
We hoped with I/O Optimized that we’d see those “40% cost savings”. After the migration, our cost savings were a whopping 90%.



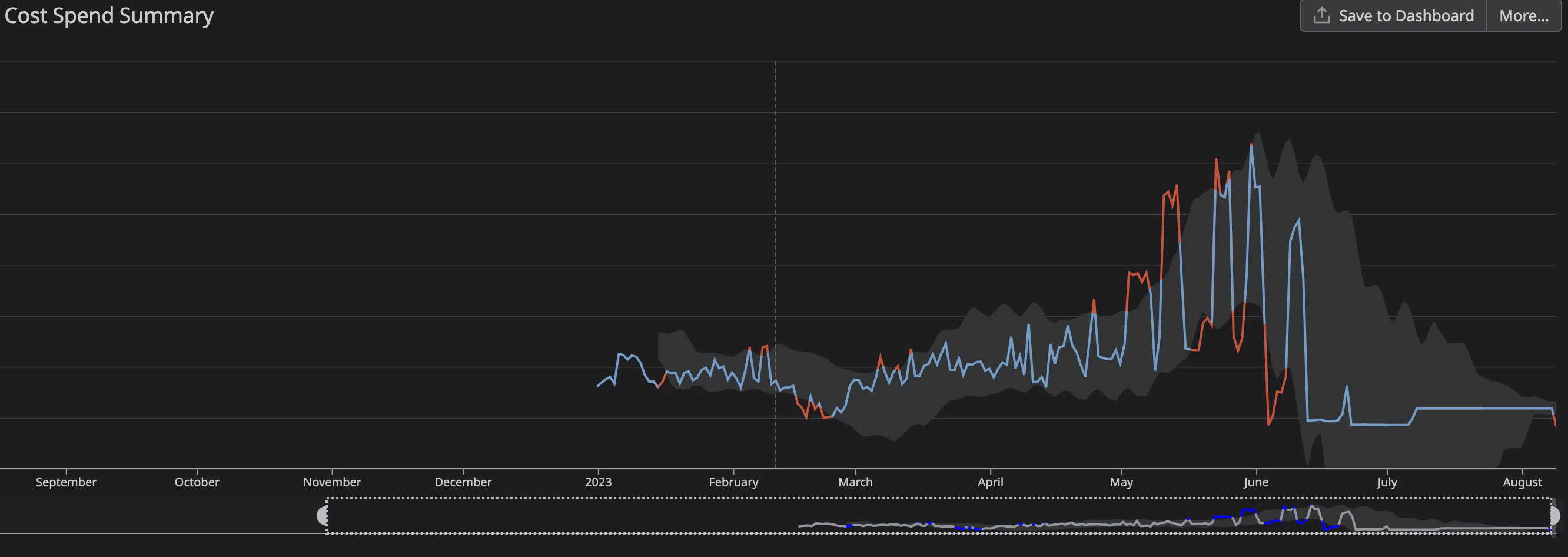
This was insane. Also, the migration itself was so simple: you can convert existing clusters with either a few clicks in the console, using the CLI, or AWS’s SDK.
We reached out to some contacts at AWS to find out why the Aurora team built this. Did I/O Optimized do some clever engineering with sharding and storing data in S3? Were they just feeling generous?
The answer we got was more the latter. The Aurora team wanted to enable more customers to run heavier I/O workloads without worrying about heavier costs.
Conclusion
We faced a massive bill on AWS due to high I/O costs, and I/O Optimized rescued us. Serverless did not benefit us as much as we expected. Hopefully our story encourages you to monitor your AWS bill, experiment with cost optimization, and keep an eye out for new features/updates from your database provider.