
One of the most important elements of development – and one key factor that separates novices from journeymen in development – is learning how to use version control. These days, version control is often taught as part of higher education in development tracks, but like many things in higher education, it’s often more taught in rote form rather than with an aim for true understanding.
In other words, many developers use Git for version control but don’t really understand how it works on an intuitive level and what it means to use the various commands at their disposal. They follow rote checklists for specific procedures, and most of the time, they work just fine. But, now and then, you may run into a situation where a different command or feature may be more useful or where simply following the ascribed procedure is likely to cause conflicts or issues.
That means it’s a good idea to take a moment and learn just what these core functionalities do and how they operate. You don’t need to know how they work on a deep, mechanical level – not unless you intend to develop Git^2, the sequel to Git – but knowing how they work on a conceptual level can help you level up your use of these features.
One of the most-used and critical features of collaboration via Git is the Merge command. Knowing how Merge works is a key piece of knowledge for effectively using Git. So, how does it work?
How a repository works
When you create a Git repository, you are creating a snapshot of a project in its current form, which commits the current state of all of the files in the project to the repository. This creates the Main commit of the project, and the start of a repository.
Main A
From there, as you continue to develop your project, you will want to save your changes from time to time. To do so, you commit those changes to the repository.
This takes a new snapshot and commits it as the new most recent commit on the Main branch.
Main A <- Main B
Each time you make a new commit, it iterates on the previous commit in an unbroken chain.
Main A <- Main B <- Main C <- Main D <- Main E […]
This is fine for an individual developer or even for a small team working with internal tools and using something like GitHub as a place to put canonical milestones for progress.
When a project grows more complex, and when individuals or teams are working on different features, bug fixes, and distinct elements of a project, they can’t all commit to the main branch.
Consider a simple project with three files: A, B, and C. Each file has a developer working on it to iterate on the features it describes. When you start, your Main branch has:
A1, B1, C1
Each developer takes the current state of the project – the commit or snapshot – and starts their work. Developer A iterates on A, Developer B iterates on B, and so on.
Now, developer B pushes their change through in a commit. You have:
A1, B2, C1
This is fine for now. But what happens when developer C wants to push their changes through in their own commit? To them, the project started as A1, B1, and C1, and they had to add C2. But, since a commit is the entire project, their commit would be A1, B1, C2. This would overwrite B2 with B1. Developer B probably wouldn’t be very happy to see their work erased! Fortunately, this issue can be solved with merges.
Rather than a simple commit, this is where branches and merging come into play. In order to understand merges, you need to understand branches.
Branching a repository
A branch is a secondary snapshot of the main repository. A branch is a reference to a commit in the main path – or whatever secondary path it’s branched off of.
In truth, we’ve already described branching above. Each developer taking the code base into their corner of the office to work on their feature is effectively branching the project off in three directions. Using the branch feature of Git is simply canonizing this procedure with version control.
When you split off a branch, the commits you make to your feature are saved in your branch but *not *in the main branch.
There’s a lot of detail to how branches work and a whole slate of mechanical concepts to understand, but the core we need to understand merging is that a branch is distinct from the Main, with iterated development on your limited feature, which is not (yet) reflected on the main.
Branches are used for a variety of reasons, generally divided into long-term and short-term. Short-term branches are branches split off and used to develop features or hotfixes for bugs and are relatively quickly merged back into the main (or working) branch.
Long-term branches, meanwhile, can be things like a “development” branch distinct from the main branch. This is used in cases where the main branch is the “live” or “production” version of the project, and commits are only pushed to it for stable, tested releases of the project. The development branch is where all of the other branches for short-term and even other long-term features are branched off of and merged back into before a stable version is tested and committed to the main.
Enter the merge
We’ve mentioned merging several times now, so it’s time to talk about what it actually means.
Remember up above when we posed the hypothetical scenario of three developers and their work overwriting one another? Merging is the official Git process that makes this much less likely.
Returning to that scenario, we have a project with three files in the main: A1, B1, and C1. Each developer branches off the main to work on their feature and file in Branch A, Branch B, and Branch C.
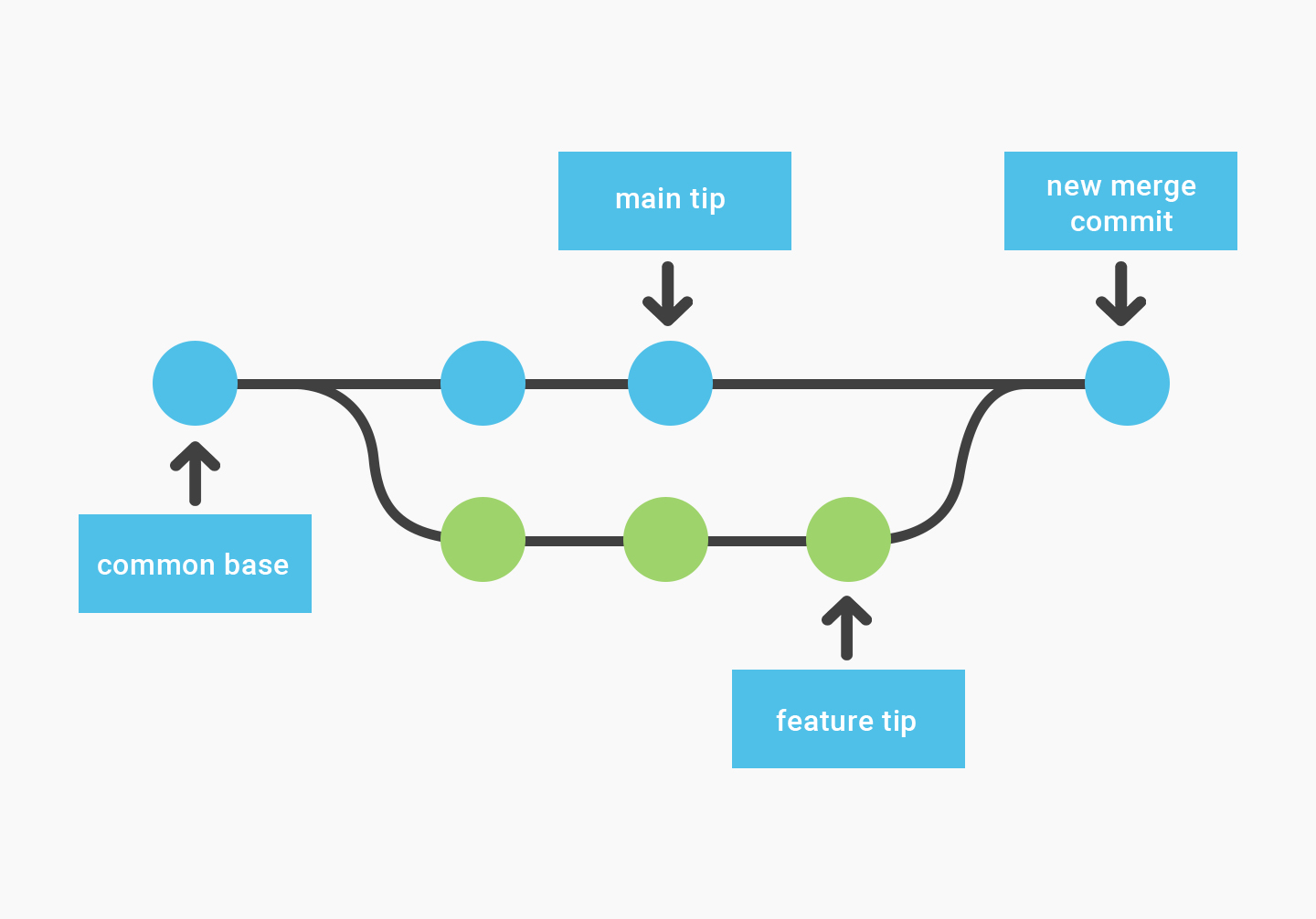
When Developer A wants to commit A2 to the main, they do so with a merge command. Git will:
Examine the Main branch.
Examine the
Abranch and identify what has changed.Check the changes against the Main.
If there are no changes to those files from the Main, merge the changes into a new commit.
In our hypothetical, you have A1, B1, and C1. When developer A has A2 ready to go in their branch, they initiate the merge to the main. Git checks and finds two things to be true:
Developer A did not make changes to
B1orC1.No one else has committed a change to
A1in the Main.
With both of these being true, it’s easy for Git to then implement the changes developer A made to A1, making the new main reflect those changes as A2, B1, and C1.
What happens to the merged branch?
Whatever the developer needs to have happen. In cases of short-term development, the developer, done with their task, can delete the branch. In other cases, such as the long-term development versus stable main scenario, the merge brings the two branches up to parity; however, work can still continue on the development branch, leaving the stable main as-is for public use. Though many diagrams such as these make it look as though the branch is deleted on the merge, it doesn’t need to be and isn’t automatic.
Now, what happens when developer B wants to update B2 to the main? In our scenario above – what would happen without version control like Git – developer B uploads their project, overwrites everything, and reverts the changes that developer A made. With Git Merge, this doesn’t happen because of the process we’ve outlined here. Git:
Checks and finds that the main has changed from
A1toA2.Checks and finds that developer
Bdidn’t make changes toAat all but did toB.Checks and finds that no one else made changes to
Bin the main.Commits a new main with the merged changes from A and B, resulting in
A2,B2, andC1.
Simple, right?
Proper merging procedure
Merging is deceptively simple, but if you make an even minor mistake, you run the risk of significant problems, including reverting all of your work and overwriting changes committed by other team members.
Therefore, it’s critical to maintain good merger habits.
Start by using
git statusto ensure that the HEAD points to the receiving branch.If necessary, use
git checkoutto switch branches.Use
git fetchto pull and validate remote commits.Use
git pullto ensure your main branch is up to date.Use
git mergeand wait for it to process.
Each of these steps helps eliminate a potential cause of a conflict or even catastrophic problem and should be part of any sanitized merge procedure.
Conflict resolution
So, what happens if someone else *did *make changes to one of those bases in the main? For example, maybe you have developers A, B, and C working on new features. In the meantime, though, someone found a critical bug with B, so another developer is working on that. Their branch, B1Bugfix, is branched off of the main. They finish their bug fix and leave the main with A1, B1 fixed, and C1.
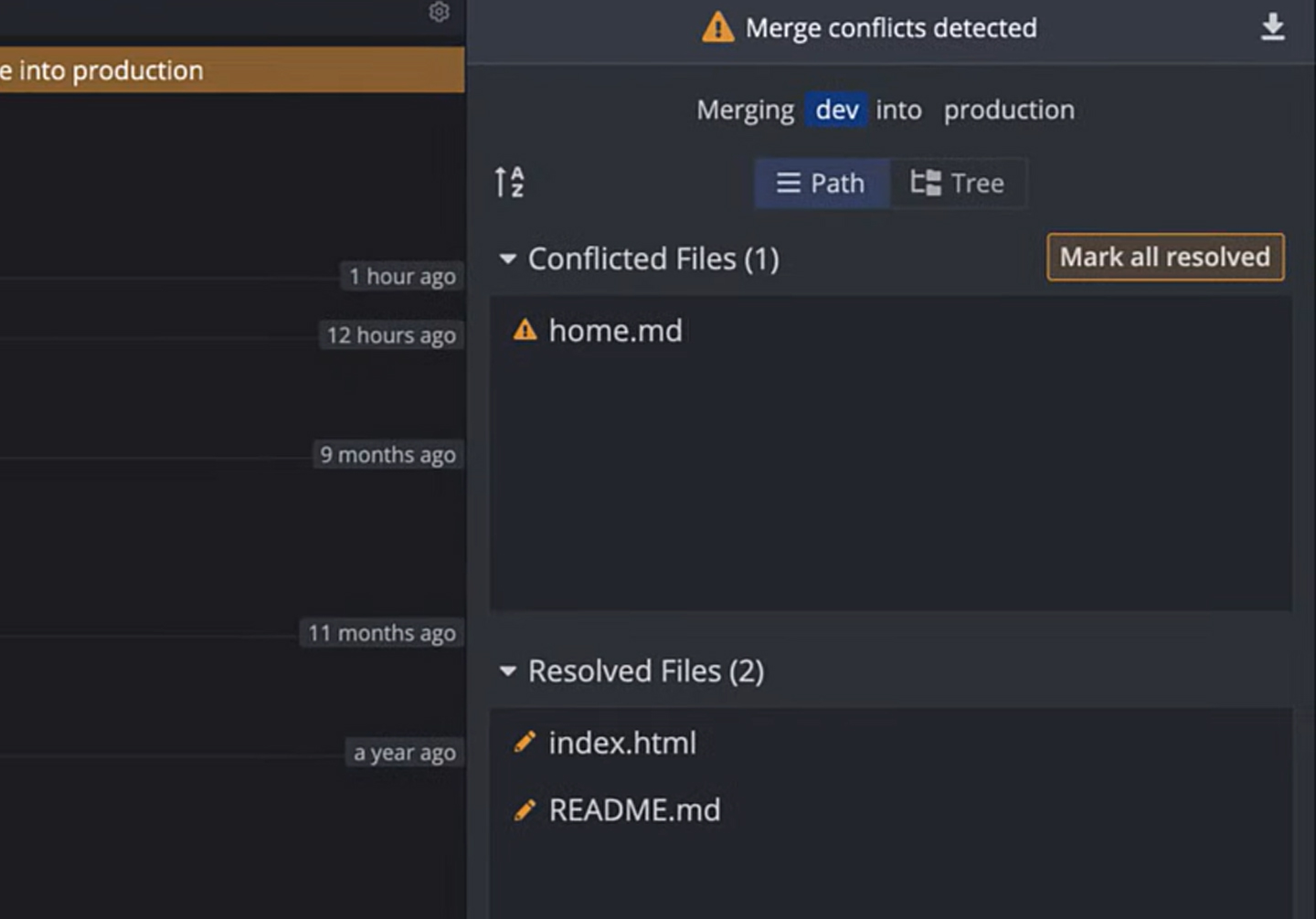
Now, when developer B needs to merge their feature to the main, there’s a conflict. Git can’t tell automatically how to merge these changes, because they are both equally valid. It’s a conflict, and the Merge command halts and notifies the developer initiating it that there’s a conflict.
What Git *can *do, though, is flag the specific lines in a file that are in conflict. It marks these using <<<<<<<, =======, and >>>>>>>, in a form that looks like this:
File content that is not affected by the conflict<<<<<<< mainFile content that is changed in the main, i.e., B1fixed=======File content that is changed in the branch, i.e., B2>>>>>>>File content that is further not affected by the conflict
While Git can identify data that conflicts, it cannot resolve that conflict. The developers in question will need to work through the conflicts, identify the resolution that preserves the changes made to the main and the changes from the feature branch, and create a new canonical main to finally merge.
Pros, cons, and alternatives
Merge is a core function of Git as version control, but it can’t do everything and doesn’t serve every purpose. An improper merge can reintroduce old bugs and revert changes, and if you aren’t careful with the merge workflow, you can accidentally merge into the wrong branch or the wrong direction, causing potentially devastating consequences.
The primary alternative to a merge is a rebase. Comparing the two is a discussion for another day, however. There are also ways to modify a merge with attributes like --squash or using a fast-forward merge. These are ways to modify the performance of a merge to circumvent or resolve particular problems.
Since one of the biggest drawbacks of merging is conflict resolution, a good collaboration and code review system is a must for any effective team. Fortunately, we can help with that.
Graphite’s powerful platform for code reviews and conflict resolution can dramatically accelerate the efficiency of your development process, and it’s easy to get up and running. Learn more here!