How CI Optimizations work
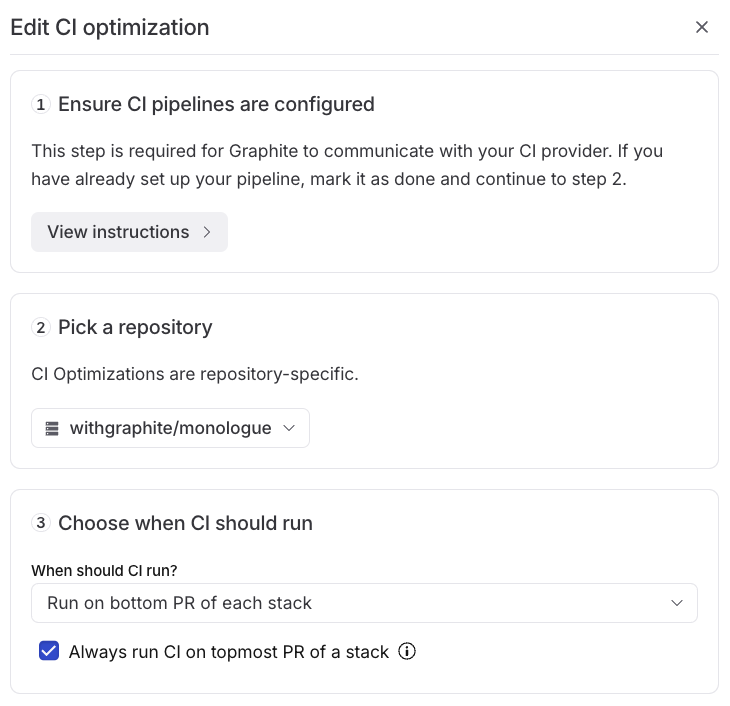
CI Optimizations is set up per-repository, and requires a very small amount of configuration, namely:- How many PRs at the bottom of each stack should run CI?
- Should CI be run at the top of the stack?
- If the request to our API is malformed or errors for any reason, we will not skip CI
- If CI Optimizations have been disabled, we will not skip CI
- If the PR is in a merge queue or merging as a stack with Graphite, we will not skip CI
How to set up CI Optimizations
To begin setting up CI Optimizations, click the “Add new” button on its settings page on the Graphite dashboard.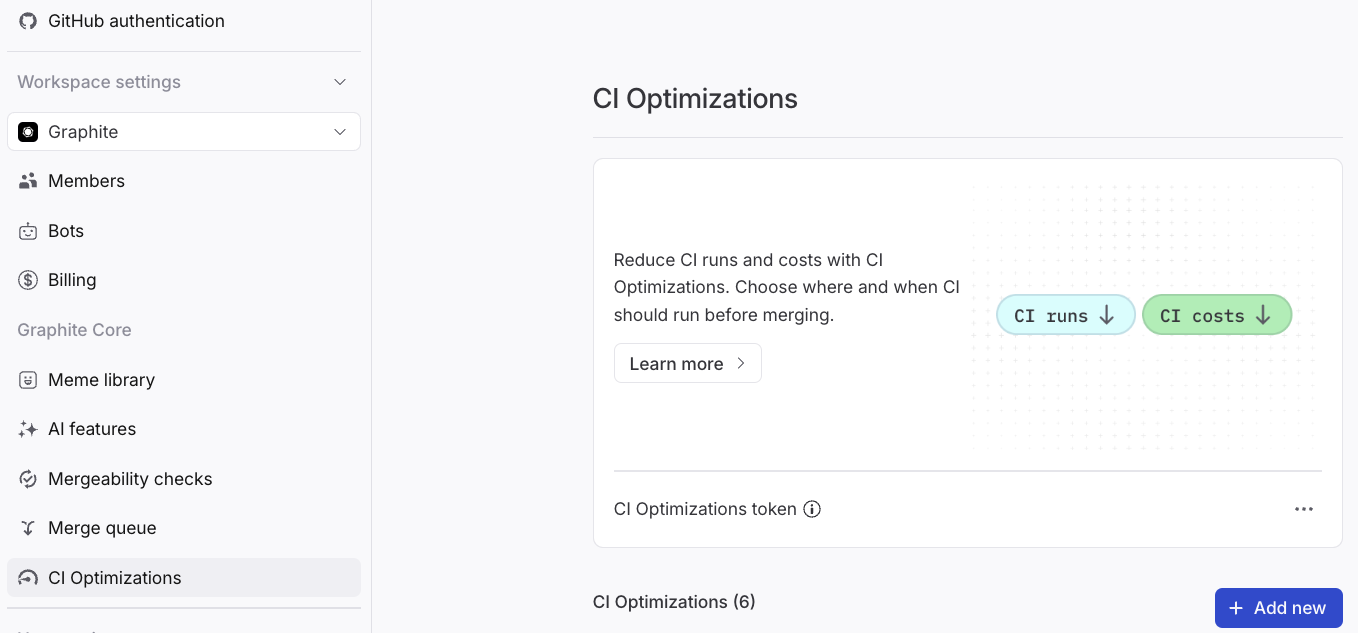
Setting up the Buildkite step
There are two ways to configure Graphite to optimize your Buildkite pipelines:Option 1: Graphite pipeline runs first (recommended)
In this Buildkite configuration, you create a new Graphite CI optimizer pipeline that runs before your repo’s other pipeline(s). It has the advantage of explicitly showing PR authors that some of their CI did not run when the optimizer skips CI.
- Create a new CI optimization in Graphite settings and copy the pipeline YAML
- In Buildkite, create a new pipeline for the same repo you configured in the previous step
-
Paste the YAML copied from Graphite into the Buildkite pipeline configuration UI or into your repo’s
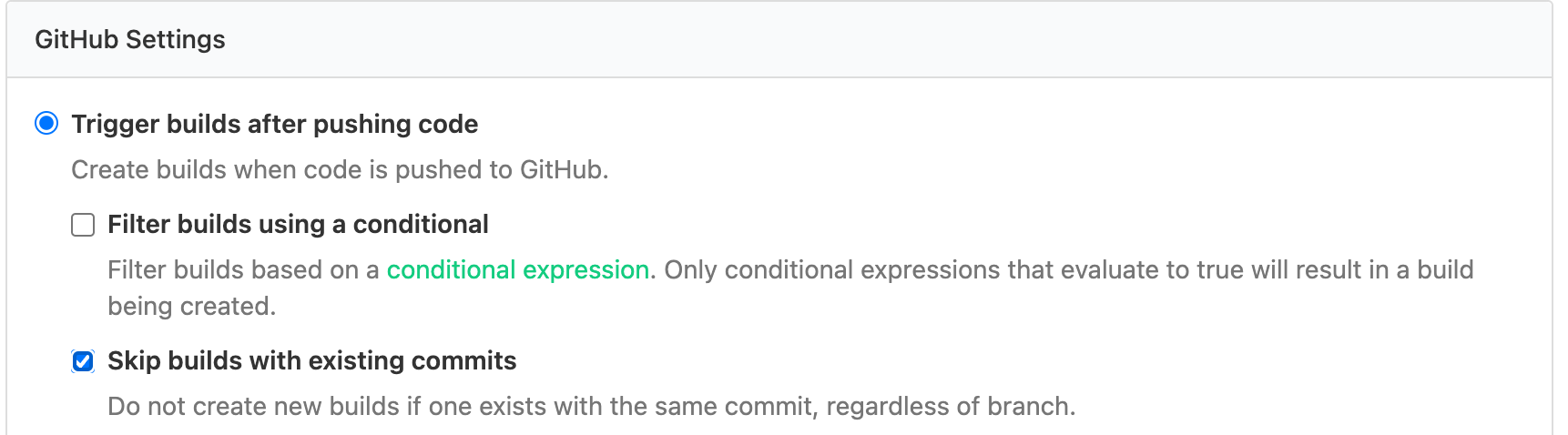
.buildkite/directory as a new pipeline. Remember to update thetriggerstep in the pasted YAML so the CI optimizer pipeline can call your own pipeline after it decides whether to optimize CI for your PR. - In your own pipeline settings under GitHub > GitHub Settings, check the box Skip builds with existing commits. This ensures the Graphite optimizer pipeline runs first and conditionally triggers your existing pipelines.
Option 2: Graphite job runs first
In this Buildkite configuration, you add a job to the start of your pipeline that your others wait for. It has the disadvantage of showing the overall pipeline status as green on GitHub, even when the CI optimizer decides to skip tests. The Buildkite and Graphite UIs show the accurate skip statuses.
- Create a new CI optimization in Graphite settings and copy the pipeline YAML
-
Add the following YAML to the beginning of your repo’s pipeline(s), including the
waitstep (pipelines are typically stored in.buildkite/). Replacegraphite_tokenwith the token from the first step.
YAML
Setting up the GitHub Actions step
- Create a new CI optimization in Graphite settings and copy the pipeline YAML
-
Add the following to your GitHub Actions workflows (typically stored in
.github/workflows/). Replacegraphite_tokenwith the token from the first step.
YAML
YAML
Error handling
Graphite’s Buildkite and GitHub Actions integrations are configured to “fail open” so that outages and errors still result in your CI running.Other ways to optimize CI
Breaking up CI
Google recommends breaking up your tests from one CI job into many which run at different points. One recommended split is:- CI that runs on all PRs
- CI that runs on PRs, excluding upstack
- CI that runs after PRs merge to main
Dependencies and test caching
If your organization doesn’t already have one set up, a dependency management tool (such as Bazel or Buck) can be really helpful. These tools look at what code changed, and determine which tests need to run as a result. This prevents unnecessary CI runs with stacking by skipping any tests that were unaffected. In a similar vein, workflow orchestration tools with caching can create a similar effect. For example, Turborepo caches CI results based on the hash of the project’s files. Unlike Bazel and Buck, all tests will still run, but if the input files were unchanged across a stack, the test will hit the cache and make the cost negligible.Required CI
If your organization has branch protection rules turned on for all base branches (instead of only trunk, for example), and you are not running CI on upstack PRs, you may see upstack PR as “missing required CI”. This is because the CI job that is required has not yet run on that PR (because it’s waiting for dependencies to be merged).Reducing CI runs with the Graphite Merge Queue
Lastly, the Graphite Merge Queue can help you save on CI cost when merging. The merge queue allows various configurations that help reduce the number of CI runs:-
Batching: CI will run just once per
batch sizestacks, wherebatch sizecan be configured in our UI. This results in a saving ofbatch size*stack heightCI runs. -
Parallel CI: Users can configure CI to run just once per stack, allowing users to save
stack heightCI runs.