What is trunk-based development?
Trunk-based development is a practice in which all developers work on a shared branch, called thetrunk or mainline using a version control system of their choice. Instead of creating long-lived feature branches, developers make changes directly to the main branch, which is continuously integrated and tested.
Continuous integration
Trunk-based development is a prerequisite for continuous integration (CI). Each time changes are pushed to thetrunk branch (which often happens several times a day), a suite of automated tests run before and after the merge to determine whether or not the change introduces regressions.
Every change to trunk triggers a build and a series of automated tests. A change that breaks your trunk branch must be fixed immediately before making any other changes—this may sound time-consuming at first, but since tests are run at each step of the development process, bugs and regressions are encountered far less frequently in a team that practices CI.
Gitflow vs. trunk-based development
Gitflow is a branching model that creates multiple long-lived branches for different stages of the development process (for example, feature branch, develop branch, release branch, and master branch). Different developers use different techniques to merge/commit between these branches, adding increased complexity to the system. Additionally, Gitflow developers work on large, long-lived feature branches for collaboration. These feature branches are often maintained for days or even months, making the merge into themain branch a tedious and risky task. These feature branches are usually so large that “code freeze” periods are required to ensure that the main branch is still in a working state, since these merge events are more prone to introducing regressions and bugs.
In contrast, trunk-based development uses a single shared branch (trunk) where all developers work and continuously integrate their changes. The model is relatively simple and agile, operating under the assumption that the trunk branch is always stable to work off of and commit to. Small batches or “stacks” of branches are extremely short-lived, and changes are merged into trunk every couple of hours.
Here’s a visual distinction between trunk-based development, and a Gitflow-style of development:
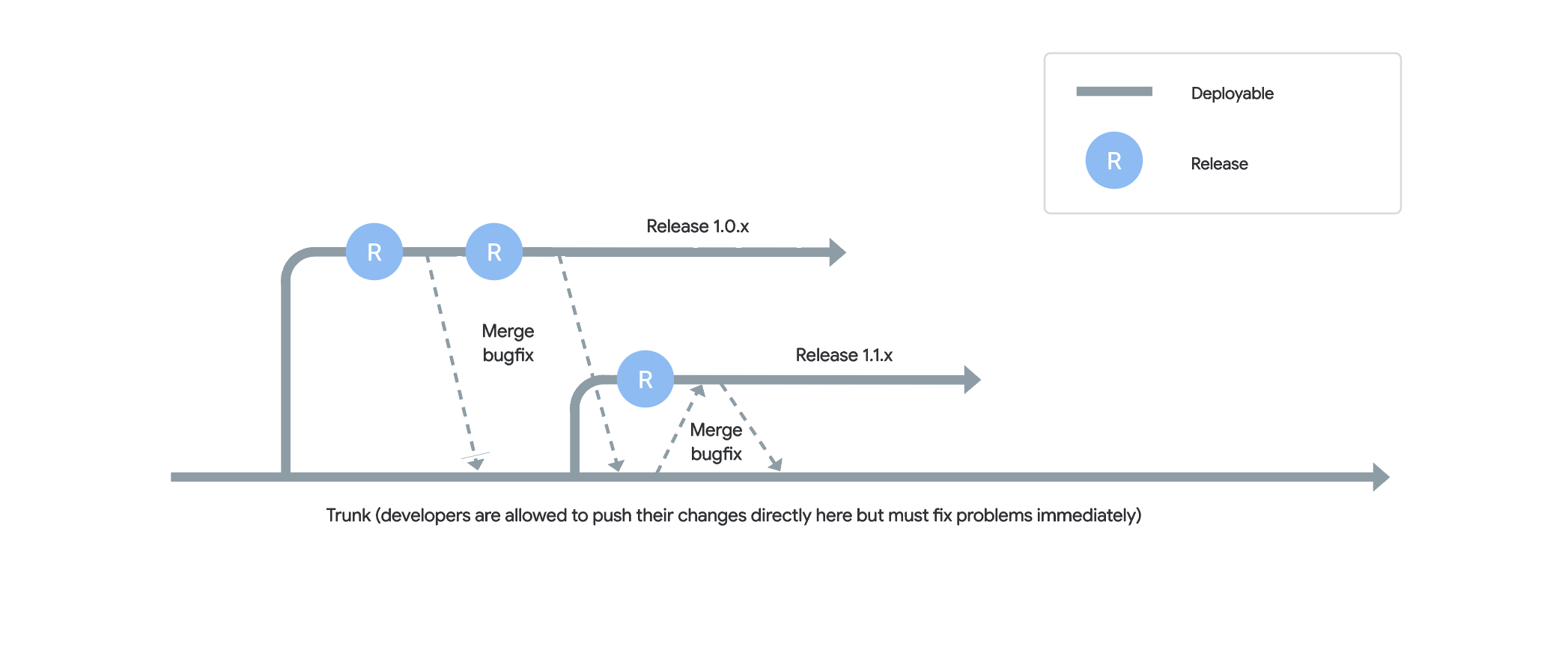
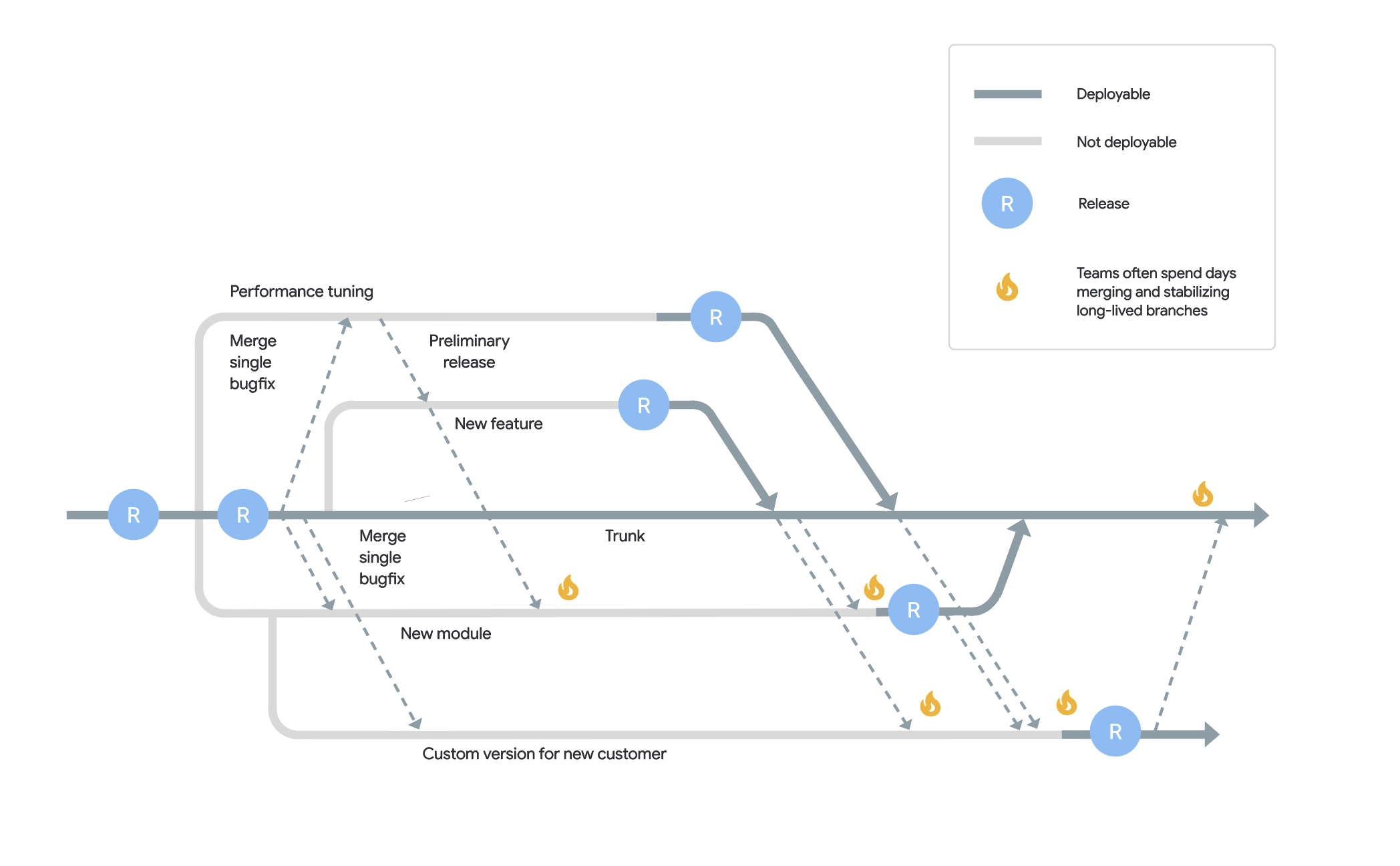
Benefits of trunk-based development
There are many benefits of trunk-based development, but these are the most notable ones:-
Fast feature delivery: In trunk-based development, changes are continuously integrated and tested (the
trunkmust always be green), so new features can be delivered faster than in a feature-branching model where features are developed in isolation and then integrated later. -
“Green” collaboration: Team members frequently update and sync their work with the
mainbranch in trunk-based development. With this approach, peers integrate each other’s changes on an hourly or minute-by-minute basis, ensuring the base they’re working off of is never stale. -
Granular code reviews: Trunk-based development encourages smaller, “stacked” changes off of
trunk, making code reviews more manageable and easier to complete. Additionally, since changes are continuously merged and tested, review feedback cycles tend to be much shorter.
Getting started with trunk-based development
Small, batched, or stacked changes
First and foremost, developers must understand how to break their changes up into small, dependent branches—those coming from a feature-branch oriented workflow may find this difficult at first.Speedy, frequent code review
The goal of trunk-based development is to merge changes as quickly as possible, while still keepingtrunk error-free. For this to happen, batched/stacked changes should be reviewed as quickly as possible, so branches exist for less than a day. The longer a branch exists, the higher the chance of introducing bugs and merge conflicts when merging the changes into trunk. Breaking up changes into smaller, dependent branches allows developers to have their code reviewed and merged while simultaneously working on new changes.
Limit the number of active branches and feature flags
Many teams have three or more active branches on a given repository—such as a develop branch, a release branch, several feature branches, and amain branch. In trunk-based development, it’s strongly recommended to keep the number of active branches to a minimum.
Since a team’s agility depends on the working status of the trunk branch, having multiple open branches makes repairing or reverting bad changes to trunk unnecessarily complicated. In situations where developers are inclined to create a feature or release branch as a gate or to develop risky features separately from the main branch, using feature flags is suggested. Feature flags wrap specific changes in an “inactive” code path and can be conditionally enabled/disabled—eliminating the need for creating another branch and instead introducing the changes directly into trunk in a non-destructive way.
Fast automated test suite and build process
To achieve CI, each commit to a repository must undergo testing before, during, and after it merges intotrunk, and subsequently trigger an automated build process. As a result, this automated test suite should consist of only short-running integration or unit or acceptance tests, and the automated build process should be quick and repeatable. Automated tests should be reliable (not flaky), and should assess the high-level functionality of the code system—and more comprehensive end-to-end tests can be run later on in development.